Modern Databases: The Architecture That’s 10x Faster Without Sacrificing Consistency

"Tech-savvy Computer Engineer with a passion for ML, NLP, and cloud solutions. AWS explorer and Full Stack problem solver—always up for a new tech challenge, one line of code at a time!"
As a developer who has spent years optimizing databases for high-traffic applications, I’ve seen a recurring pattern: traditional relational databases struggle once real scale hits. Vertical scaling becomes limiting, failovers are slow, and there’s always a trade-off between performance and consistency.
Then I discovered modern databases — specifically Amazon Aurora and DynamoDB — and everything changed.
These aren’t just “managed versions” of MySQL or PostgreSQL. They represent a complete architectural revolution: the decoupling of compute from storage. This single design decision delivers massive performance gains, true elasticity, and operational simplicity that legacy systems simply cannot match.
In this deep-dive, I’ll walk you through why modern databases are fundamentally different, how they work under the hood, their real-world benefits, and when you should migrate.
1. Traditional Databases: The Monolithic Era
Classic databases like MySQL and PostgreSQL were designed for a pre-cloud world. Everything — CPU, memory, and storage — lived on the same machine.
When load increased:
The entire instance slowed down.
You had to upgrade the whole server (expensive and disruptive).
Failover was slow and painful.
Scaling read replicas required complex replication management.
Here’s what that architecture looks like in practice:

RDS PostgreSQL Multi-AZ setup (traditional model). Synchronous replication across AZs, but everything is still tightly coupled to the primary instance.
This monolithic design worked great for small-to-medium workloads. But at scale? It becomes a bottleneck.
2. Modern Databases: Compute-Storage Decoupling
Modern databases flip the script entirely.
Compute Layer (handles queries, transactions, caching)
Storage Layer (only responsible for durable, replicated storage)
They communicate over the network, but they scale independently.
This is the core innovation behind Amazon Aurora, Google Spanner, and DynamoDB.

Amazon Aurora’s decoupled architecture in detail. The compute node only sends redo logs to the distributed storage layer — no full data pages, no checkpoint stalls.
The storage layer uses sophisticated techniques (Aurora’s famous 6-way replication across 3 AZs with quorum writes) to ensure durability while keeping the compute layer lightweight and fast.

Shared storage volume across Availability Zones. Writer and reader instances share the exact same storage — enabling instant failover and read scaling.
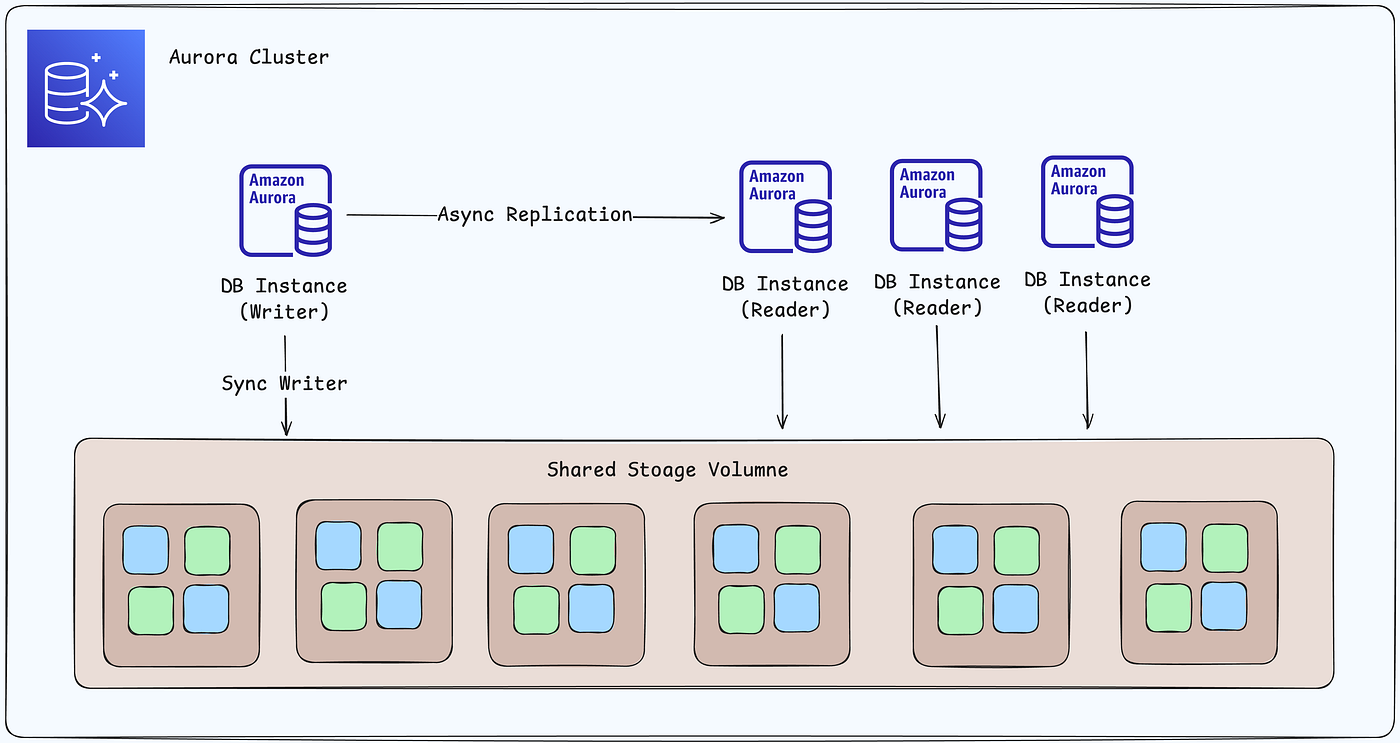
Simple view of an Aurora cluster: One writer instance + multiple reader instances, all backed by the same shared storage volume.
3. The Game-Changing Benefits
This architectural shift unlocks capabilities that were impossible in traditional databases:
Independent Scaling: Need more query throughput? Spin up more compute nodes. Storage stays untouched.
Super-Fast Failover: If the primary compute node fails, another one takes over in seconds — because storage is already consistent and shared.
Instant Read Replicas: Add readers almost instantly. No heavy replication lag.
Serverless-like Billing: Pay only for the compute and storage you actually use.
Resilience by Design: Storage node failures don’t bring down your database.
Here’s Aurora PostgreSQL in action across multiple AZs:

Writer + readers across three Availability Zones, all connected to the same distributed storage nodes with continuous backups to S3.
4. The Distributed Systems Reality (The Trade-Off)
Of course, nothing is free.
In modern databases, writes travel over the network to multiple storage nodes. The final commit latency is determined by the slowest node in the quorum. This is the classic challenge of distributed systems — network variability becomes part of the equation.
But Aurora has engineered clever solutions:
Quorum-based writes (4 out of 6 copies in Aurora)
Log-only shipping instead of full page writes
Optimized networking within AWS regions
The result? You still get strong consistency, but with dramatically higher throughput.
5. When Should You Choose Modern Databases?
Choose Aurora / Google Spanner / DynamoDB when you need:
High availability and sub-second failover
Massive read scale (hundreds of readers)
Predictable performance at cloud scale
Pay-as-you-go economics
Multi-AZ or multi-region resilience
Stick with traditional RDS (MySQL/PostgreSQL) only for:
Very small workloads
Legacy applications with complex stored procedures
Teams that prefer full control over the database engine
Final Thoughts
Modern databases aren’t just an incremental improvement — they’re a paradigm shift in how we think about data persistence in the cloud era.
The decoupling of compute and storage is the same kind of leap that containers brought to compute and S3 brought to object storage. Once you experience it, going back to monolithic databases feels old-fashioned.
As someone building systems that need to scale reliably, I’ve made a plan to switch to Aurora. The performance, resilience, and developer experience are simply unmatched.
If you’re still running self-managed MySQL/PostgreSQL or even the older RDS models, it might be time to rethink your stack.
The future of databases is decoupled, distributed, and cloud-native.
What’s your experience with modern databases? Have you migrated to Aurora or Spanner yet? Drop your thoughts in the comments — I’d love to hear how these architectures are shaping your projects.
Tags: Amazon Aurora, Modern Databases, Compute-Storage Decoupling, Cloud Architecture, Database Scaling, PostgreSQL, MySQL, Distributed Systems
This post is part of my ongoing series on cloud-native architecture and system design. Follow for more deep-dives into scalable systems.